 |
 |
🛴 |
![]()
A quaternion is a four-dimensional complex number
An arbitrary orientation of frame B relative to frame A
![]()
The coordinate system {A} is rotated by θ relative to the ![]()
![]() direction is called the coordinate system {B}, it is called the quaternion
direction is called the coordinate system {B}, it is called the quaternion ![]()
![]() .
.
![]()
![[Graphics:math/1_Quaternion/index_8.gif]](math/1_Quaternion/index_8.gif)
![]()
![]()
Angle
![]()
normalized four-dimensional vector
![]()
the quaternion paramentrization obeys
![]()
hypercomplex numbers {i,j,k}
![]()
![]()
![]()
![]()
![]()
A quaternion conjugate
![]()
A quaternion product ⊗
![]()
![]()
Hamilton rule

proof
![]()
![]()

![]()
![]()
![]()
![]()
![]()


Euler axis
![]()
Vector's Elements
![]()
![]()
![]()
![]()
Half Angle Identities
![]()
![]()
![]()
Norm
![]()
![]()
Inverse
![]()
![]()
A three dimensional vector
![]()
![[Graphics:math/1_Quaternion/index_46.gif]](math/1_Quaternion/index_46.gif)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Derivative of Quaternion
![]()
![]()

Orthogonal matrix
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Transpose = Inverse
![]()
![[Graphics:math/2_RotationMatrix/index_11.gif]](math/2_RotationMatrix/index_11.gif)
![]()
A three dimensional vector
![]()
![[Graphics:math/2_RotationMatrix/index_14.gif]](math/2_RotationMatrix/index_14.gif)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Inner Product Space
![]()
![]()
Representation of orientation

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The coordinate system {A} is rotated by θ relative to the ![]()
![]() direction is called the coordinate system {B}, it is called the rotation matrix
direction is called the coordinate system {B}, it is called the rotation matrix ![]() R.
R.

Rotation Matrix: Direction Cosine Matrix

![]()

![]()
Properties of rotation matrix
![]()
![]()
![]()
![Overscript[x,^] _A = ({{^Ax_x}, {^Ax_y}, {^Ax_z}}) ; Overscript[y,^] _A = ({{^Ay_x}, {^Ay_y}, {^Ay_z}}) ; Overscript[z,^] _A = ({{^Az_x}, {^Az_y}, {^Az_z}}) ;](math/2_RotationMatrix/index_47.gif)
![Overscript[x,^] _B = ({{^Bx_x}, {^Bx_y}, {^Bx_z}}) ; Overscript[y,^] _B = ({{^By_x}, {^By_y}, {^By_z}}) ; Overscript[z,^] _B = ({{^Bz_x}, {^Bz_y}, {^Bz_z}}) ;](math/2_RotationMatrix/index_48.gif)


![]()
![]()
![]()
![]()


![]()
![]()
![]()
Z-Y-X 오일러 각 (이동 좌표계)
![]()
→모든 회전이 이동 좌표계에 대한 회전을 이용한 상대변환이므로 해당 변환행렬을 앞에서부터 순차적으로 곱한다.
![[Graphics:math/3_EulerAngle/index_4.gif]](math/3_EulerAngle/index_4.gif)
Roll-Pitch-Yaw (고정 좌표계)
→고정기준좌표계{A}의 X축에 대해 φ만큼 회전 후 고정좌표계의 Y축에 대해 θ만큼 회전한 후,
고정좌표계의 Z축에 대해 ψ만틈 연속적으로 회전을 하여 특정방위를 나타내는 좌표계{B}를 얻는 방법
→모든 회전이 고정 기준 좌표계에 대한 회전을 이용한 절대변환이므로 해당 변환행렬을 뒤에서부터 앞으로 역순으로 곱한다.
![[Graphics:math/3_EulerAngle/index_5.gif]](math/3_EulerAngle/index_5.gif)
![]()
![]()
![]()
![]()
![]()
![]()
Rotation Matrix ![]() R → Roll φ
R → Roll φ![]() ,Pitch θ
,Pitch θ![]() ,Yaw ψ
,Yaw ψ![]()
![]()
→the three RPY angles are (θ∈(-π/2,π/2))
![]()
![]()
![]()
→or (θ∈(π/2,3 π/2))
![]()
![]()
![]()
x,y,z
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()

![]()

![]()

![]()
![]()
![]()
![]()
![]()
Rotation Matrix ![]() R → Quaternion
R → Quaternion ![]()
![]()

1
![]()
![]()
2
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
3
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Euler Angle (Roll φ ![]() , Pitch θ
, Pitch θ ![]() , Yaw ψ
, Yaw ψ ![]() , ZYX) → Quaternion
, ZYX) → Quaternion ![]()
![]()
![]()
![]()
![]()
![]()
1
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
2
![]()
![]()
![]()
![]()
3

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
4

![]()

5
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

γ/ϑ → ![]()


Rotation Matrix ![]() R
R
![[Graphics:math/2_RotationMatrix/index_59.gif]](math/2_RotationMatrix/index_59.gif)
![]()
1
![]()
2
![]()
![]()
3
![]()
![]()
4
![]()

5

Rotation Matrix ![]() R → Axis γ/Angle ϑ
R → Axis γ/Angle ϑ
![]()
![]()
![]()
![]()
Orientation ![]()
![]() → Axis γ/Angle ϑ → Rotation Matrix
→ Axis γ/Angle ϑ → Rotation Matrix ![]() R
R
![]()

Half-Angle Identities
![]()
![]()
![]()
![]()
![]()
1
![]()
![]()
![]()
![]()
2
![]()
![]()
![]()
![]()
3
![]()
![]()
![]()
![]()
4
![]()
5
![]()
![]()
![]()
![]()
6
![]()

7

8

9
![]()


![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]()
Orientation from angular rate
A tri-axis gyroscope
Angular rate
![]()
Quaternion
![]()
Measured at time t
![]()
![]()
Orientation of the earth frame at time t
![]()
The samling period Δt
![]()
Gyroscope bias drift compensation
With temperature and motion
Karman-based approaches → estimate the gyroscope bias
Mahony et al → gyroscope bias drift (the integral feedback of the error)
Normalized direction of the estimated error in the rate of change of orientation ![]()
![]()
Gyroscope bias ![]()
![]()
![]()
The integral gain ζ
DC component of ![]()
![]()
![]()
![]()
![]()

Gyroscope measurements ![]()
![]()
![]()
![]()
![]()
Filter gains
![]()
Filter gain
![]()
Estimated rate of gyroscope bias drift in each axis ![]()
Filter gain
![]()
Jacobian matrix and determinant
![]()
![]()
![]()
![]()

Gradient descent (Linear system)
![]()
![]()
![]()
![]()
![]()
Orientation from vector observations
A tri-axis accelerometer (Linear accelerations due to motion)
![]()
A tri-axis magnetometer (Local magnetic flux and distortions)
![]()
Quaternion
![]()
Predefined reference direction
![]()
Measured direction
![]()
Objective function
![]()
Quaternion may be found
![]()
Gradient descent algorithm
Orientation estimation of ![]()
![]()
![]()
step-size: α
Gradient of the solution surface (General form)
![]()
Objective function
![]()
![]()
![]()
![]()
![]()




Jacobian matrix


Gradient of the solution surface (General form)
![]()
![]()


Calculation induction




Direction of gravity (Vertical axis, z axis)
Appropriate convention (the equations simplify)
![]()
Normalized accelermeter measurement
![]()
Objective function

Jacobian matrix
![]()
Earth's magnetic field (One horizontal axis, Vertical axis)
Appropriate convention (the equations simplify)
![]()
Normalized accelermeter measurement
![]()
Objective function

Jacobian matrix
![]()
Magnetic distortion compensation
Declination errors
Horizontal plane:earth's surface (Heading)
Inclination errors
Vertical plane: earth's surface (Sensor's attitude)
The measured direction of the earth's magnetic field in the earth frame at time t
![]()
![]()
![]()



![]()
![]()
Solution surface → minimum
![]()
Objective function
![]()

Jacobian matrix
![]()

Gradient of the solution surface (General form)
![]()


Estimate orientation ![]()
![]()
![]()
![]()
Convergence rate governed by ![]() ≥ Physical rate
≥ Physical rate
![]()
Objective function gradient
![]()
![]()
![]()
Optimal value of the step-size
![]()
Filter fusion algorithm
Estimated orientation
![]()
![]()
![]()
![]()
![]()
![]()
![]()
η, ![]()
| == | ||
| η |
Magnitude of a quaternion derivative == Gyroscope measurement error
![]()
![]()
Optimal fusion
![]()
![]()
![]()
Simplify
Estimated orientation
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Estimated orientation rate ![]()
![]()
Rate of change of orientation measured by gyroscopes ![]()
![]()
Direction of the estimated error ![]()
![]()
Simplified to equation
![]()
Estimated rate of change of orientation
![]()
Quaternion derivative measured at time t
![]()
Direction of error of ![]()
![]()
![]()
Objective function
![]()

Jacobian matrix
![]()

Gradient of the solution surface (General form)
![]()
![]()


Calculation induction

![]()

![]()

IMU (Inertia Measurement Unit) algorithm
![[Graphics:math/4_IMU/index_151.gif]](math/4_IMU/index_151.gif)
Least Squares LR (Linear Regression)
y=![]() +
+![]() x
x
1
![]()
![]()
2
![]()
![]()
3
![]()
4
![]()
![]()
![]()
y=![]() +
+![]() x1+
x1+![]() x2
x2
1
![]()
![]()
2
![]()
![]()
3
![]()
4
![]()
![]()
![]()
Multivariate Regression
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
Magnetic sensor Soft/Hard Iron
Elliptical Sphere
![]()
![]()
![]()
![({{a}, {b}, {c}}) = ( {{W[[4]]/W[[1]]}, {W[[5]]/W[[2]]}, {W[[6]]/W[[3]]}} )](math/4_IMU/index_185.gif)
Sphere
![]()
![]()
![]()
![({{a}, {b}, {c}}) = ( {{W[[2]]/W[[1]]}, {W[[3]]/W[[1]]}, {W[[4]]/W[[1]]}} )](math/4_IMU/index_189.gif)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
W=![]() (xy)
(xy)
![]()
![]()

![]()
![]()
1
![]()
![]()
![]()
![]()
2
![]()
![]()
![]()

3
![]()
![]()
![]()

4

![]()
![]()

t
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
W=![]() (xy)
(xy)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Elliptical Sphere
![]()
![]()
![]()
![({{a}, {b}, {c}}) = ( {{W[[4]]/W[[1]]}, {W[[5]]/W[[2]]}, {W[[6]]/W[[3]]}} )](math/4_IMU/index_255.gif)
W=![]() (xy)
(xy)
![]()
1
![]()
![]()
![]()
![]()
2
![]()
![]()
![]()

3
![]()
![]()
![]()

t
![]()
![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
Artificial Intelligence (AI)
Machine Learning
Deep Learning
![[Graphics:math/5_Training/index_1.gif]](math/5_Training/index_1.gif)
Function Composition
![]()
Fully-connected network (FC-net)
![]()
Convolutional neural network (CNN)
![]()
Recurrent neural network (RNN)
![]()
Explosion
![]()
![]()
![]()
![]()
Gradient
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Linear Models
Universal Approximation
![]()
Model = Approximation
![]()
![]()
![]()
Linear Models
Linear regression
Regularization
![]()
![]()
![]()
Binary Classification
Logistic Regression
![]()
![]()
![]()
![[Graphics:math/5_Training/index_28.gif]](math/5_Training/index_28.gif)
![]()
![]()
![]()
![]()
Linear models for regression
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Problem Setup
![]()
![]()
![]()
Basic Function
![]()
Linear models
![]()
Neural networks
![]()
Kernel regression
![]()
Least Squares Method
![]()
![]()
![]()
![]()

![]()
![]()
![]()
Regularization
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Ridge Regression
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Find λ
![]()
![]()
Illusstration
![]()
Logistic Regression
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Logistic Regression
![]()
![]()
![]()
![]()
![]()
![]()
Error function
![]()
![]()
![]()
![]()
Cross entropy error
![]()
![]()
![]()
![]()
ex
![]()
![]()
![]()
Logistic Regression:MLE
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Logistic Regression:IRLS
![]()
| Δw=- | ||
| gradient,∇J[w] |
![]()
![]()
![]()

Multiclass Extension: Softmax Regression
![]()
Feedforward Nets
Linear classification
A linear discriminant function which has the form
![]()
![]()
Decision rule is given by sgn[f[x]]
![]()
Separating hyperplane
![]()
![]()
Perceptron
A single layer neural network
The first iterative algorithm for learning linear classification
![]()
Perceptron convergence Theorem
![]()
![]()
![]()
![]()
![]()
Perceptron Criterion
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
objective function
![]()
Gradient descent
![]()
![]()
![]()
Perceptron Learning: A Basic Idea
![]()
![]()
![]()
![∂[w]/∂w = ({{∂[w]/∂w_1}, {∂[w]/∂w_2}, {:}, {∂[w]/∂w_m}}) ∈^m](math/5_Training/index_152.gif)
Perceptron Learning: Algorithm Outline
![]()
![]()
![]()
![]()
![]()
![]()
McCulloch-Pitts Model
![[Graphics:math/5_Training/index_159.gif]](math/5_Training/index_159.gif)
Activation Functions
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Multilayer Perceptron (MLP)
Structure: bipartite
![[Graphics:math/5_Training/index_168.gif]](math/5_Training/index_168.gif)
![]()
![]()
Square loss (error)
![[Graphics:math/5_Training/index_171.gif]](math/5_Training/index_171.gif)
![]()
![]()
Sematic space
Backpropagation
![]()
![]()
![]()
![]()
![[Graphics:math/5_Training/index_178.gif]](math/5_Training/index_178.gif)
![]()
![]()
![]()
![]()
![]()
![[Graphics:math/5_Training/index_184.gif]](math/5_Training/index_184.gif)
![[Graphics:math/5_Training/index_185.gif]](math/5_Training/index_185.gif)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![[Graphics:math/5_Training/index_200.gif]](math/5_Training/index_200.gif)
Image Classification
![]()
![]()
![]()
Training
Optimization for deep learning
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Gradient descent
![[Graphics:math/5_Training/index_212.gif]](math/5_Training/index_212.gif)
![]()
A first-order iterative optimization algorithm for finding a local minimum of the objective function J[θ]
Moves from the current values of parameters, ![]() , in the opposite direction of the gradient of the objective function J[θ] w.r.t. the parameters, evaluated at
, in the opposite direction of the gradient of the objective function J[θ] w.r.t. the parameters, evaluated at ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
(Full) Batch Gradient Descent ⇔ Vanilla Gradient
Resort to entire training dataset to compute the gradient of the object function
![]()
The accuracy of the parameter update is high but it can be slow
Intractable for datasets that do not fit in memory
Does not allow us to update the model online (with new examples on the fly)
Mini-Batch Gradient Descent ⇔ Stochastic Gradient descent (SGD)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Gradient=Steepest Descent Direction
![]()
![]()
![]()
![]()
By the Lagrangian method, we have
![]()
![]()
![]()
![]()
Convex function
![]()
![]()
![]()
Neural Network ![]() [x]
[x]
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Iterative methods
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Problem
![]()
![]()
![]()
![]()
![]()
General form of iteration methods
![]()
![]()
![]()
Definition
![]()
![]()
![]()
Lemma
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Exponentially Weighted Moving Average
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Bias Correction
![]()
![]()
![]()
![]()
Gradient Descent with Momentum
![]()
![]()
![]()
![]()
![]()
![]()


![]()
![]()
![]()
![]()
Manhattan-Learning Rule
![]()
![]()
![]()
![]()
![]()

![]()
Resilent Backprop (Rprop)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()

![]()
AdaGrad: Adaptive Gradient
![]()
![]()
![]()
![]()
![]()
RMSProp
![]()
![]()
![]()
![]()
![]()
![]()
![]()
ADAM Optimization
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Learning Rate Decay (Step Size)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Dropout
![]()
![]()
Normalization
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Batch Normalization
![]()
![]()
![]()
![]()
![[Graphics:math/5_Training/index_370.gif]](math/5_Training/index_370.gif)
BN is applied to individual dimension for each mini-batch of size M
![]()
![]()
![]()
![]()
![]()
Rescale and shift by learnable parameters
![]()
![]()
![[Graphics:math/5_Training/index_378.gif]](math/5_Training/index_378.gif)
![]()
BN in Inference Phase
![]()
![]()
![]()
![]()
![]()
![]()
Layer Normalization
![]()
![]()
![]()
![]()
![]()
![σ_t^(l) = (1/HUnderoverscript[∑, i = 1, arg3] (a_ (i, t)^(l) - μ_t^(l))^2)^(1/2)](math/5_Training/index_391.gif)
![]()
![]()
![]()
CNN (Convolutional Neural Network)
Convolutional Neural Network (CNN)
![]()
![]()

![]()
![]()
![]()
Pre-trained CNNs: before Freeze, Change Output (Transfer learning)
![]()
![]()
LeNet-5
![]()
Operations
![]()
![]()
![]()
ResNet
![]()
![]()
![]()
![]()
Inception Net
![]()
![]()
Convolutions
Padding
![]()
![]()
Strided Convolution
![]()
![]()
Convolution over Volume
![]()
1×1 Convolution
![]()
![]()
Max Pooling
![]()
![]()
Semantic Segmentation
![]()
![]()
Fully Convolutional Networks
![]()
![]()
Conv+Deconv
![]()
![]()
Upsampling
![]()
![]()
Nearest Neighbor
![]()

Bed of Nails

Max unpooling
![]()

Deconvolution or Transposed Convolution
![]()
![]()
![]()
![]()
![]()
![]()
e.x.1
![]()
![]()
![]()
![]()
| 0 | a | b | c | d | 0 |

e.x.2
![]()
![]()
![]()


Residual Block
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Mitigate vanishing gradients:
![]()
Skip Connections
Identity shortcuts:
![]()
![]()
when dimensions change
![]()
![]()
![]()
Inception Nets
Naive Version
![]()
![]()
![]()
![]()
![]()
![]()
With Dimension Reduction
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Object Detection: Localization + Classification
![]()
![]()
![]()
R-CNN:Regions with CNN features
![]()
YOLO
![]()
![]()
![]()
![]()
CNN for Time Series Classification
![]()
![]()
![]()
![]()
![]()
RNN (Recurrent Neural Network)
IID Data (Independent, Identically, Distributed)
![]()
![]()
![]()
![]()
Sequence Modeling
![]()
Non IID Data
![]()
![]()
![]()
![]()
![]()
Feedforward Net
![[Graphics:math/7_RNN/index_11.gif]](math/7_RNN/index_11.gif)
![]()
![]()
Vanilla RNN: Unfolding Computational Graph
![]()
![[Graphics:math/7_RNN/index_15.gif]](math/7_RNN/index_15.gif)
![]()
![]()
Hidden Markov Model
![[Graphics:math/7_RNN/index_18.gif]](math/7_RNN/index_18.gif)
Many to Many: Encoder-Decoder
![[Graphics:math/7_RNN/index_19.gif]](math/7_RNN/index_19.gif)
![[Graphics:math/7_RNN/index_20.gif]](math/7_RNN/index_20.gif)
Seq-to-Seq Learning
![]()
![]()
![]()
![]()
![[Graphics:math/7_RNN/index_25.gif]](math/7_RNN/index_25.gif)
Aligment Model
| → | ||||
| FF Net | → | |||
| → |
![]()
Vanilla RNN: Gradient Flow
![[Graphics:math/7_RNN/index_30.gif]](math/7_RNN/index_30.gif)
![]()
![]()
![]()
![]()
![[Graphics:math/7_RNN/index_35.gif]](math/7_RNN/index_35.gif)
![]()
![]()
![]()
![]()
![]()
Attention in Encoder and Decoder
Encoder
![]()
![]()
Decoder
![]()
![]()
![]()
Encoder-decoder attention
![]()
![]()
![]()
Hidden vector
![]()
Long Short Term Memory (LSTM)
![]()
Permutation-Equivariant Attention Modules (SAB & ISAB)
MAB (multihead attention block)
![]()
![]()
![]()
SAB (set attention block)
![]()
ISAB (induced set attention block)
![]()
![]()
![]()
Gates ∈ [0,1]
LSTM Cell Updates
![]()
![]()
![]()
![]()
![]()
![]()
![]()
LSTM: Gradient Flow
![[Graphics:math/7_RNN/index_65.gif]](math/7_RNN/index_65.gif)
![]()
![]()
![]()
Gated Recurrent Unit (GRU)
![]()
![]()
![]()
![]()
![]()
![]()
Generative RNN
![]()
![]()
Likelihood
![]()
Loss function
![]()
VAE
GAN
Generating Sequence
![[Graphics:math/7_RNN/index_79.gif]](math/7_RNN/index_79.gif)
Training RNNs for sequence Prediction
![]()
![]()
![]()
![]()
![]()
Training
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Teacher-Forcing
![]()
TF
![[Graphics:math/7_RNN/index_93.gif]](math/7_RNN/index_93.gif)
Without TF
![[Graphics:math/7_RNN/index_94.gif]](math/7_RNN/index_94.gif)
![]()
![]()
Attention in RNN-Encoder-Decoder
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![[Graphics:math/7_RNN/index_109.gif]](math/7_RNN/index_109.gif)
![]()
![]()
![]()
| → | ||||
| FF Net | → | |||
| → |
![]()
Visual Attention
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Encoder
![]()
![]()
![]()
Decoder
![]()
Tranformer models
![]()
RNN
![]()
CNN (ByteNet, ConvS2S)
![]()
Vanilla Transformer
![]()
![]()
Self-Attention: A sequence-to-sequence operation
![]()
![]()
![]()
![]()
![]()
Query, Key, Value
![]()
![]()
![]()
![]()
Scaled Dot-Product Attention
![]()
![]()
![]()
![]()
![]()
![Underoverscript[∑, n = 1, arg3] (Exp[q_ik_n/D_k^(1/2)]/(Underoverscript[∑, j = 1, arg3] Exp[q_ik_j/D_k^(1/2)])) v_n](math/7_RNN/index_148.gif)
![]()
![]()
Multi-Head Attention
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Position-wise Feedforward Networks
![]()
![]()
![]()
![]()
![]()
Positional Encoding
![]()
![]()
![]()
![]()
![]()
Reformer: Efficient Transformer
Transformer models
![]()
![]()
Reformer models
![]()
![]()
![]()
Locality Sensitive Hashing (LSH)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Reversible Network
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![[Graphics:math/7_RNN/index_194.gif]](math/7_RNN/index_194.gif)
![[Graphics:math/7_RNN/index_195.gif]](math/7_RNN/index_195.gif)
Autoencoder
Permutation Invariance and Equivariance
![]()
Wanted
![]()
![]()
Definition (Permutation invariance)
![]()
![]()
Definition (Permutation equivariance)
![]()
![]()
Permutation Equivariant Functions
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Amortized Clustering
![]()
![]()
Attention Operaotors
Dot-product attention
![]()
![]()
![]()
Multihead attention
![]()
![]()
![]()
![]()
![]()
Set Transformer: Encoder & Decoder
Encoder ( X → Z )
![]()
![]()
![]()
Pooling by Multihead Attention (PMA)
![]()
![]()
Decoder ( Z → y )
![]()
![]()
Deep Generative models
![]()
![]()
Latent Space = Hidden space=Invisible space
![]()
Observed space
A Powerful model for unsupervised learning
![]()
![[Graphics:math/8_Autoencoder/index_36.gif]](math/8_Autoencoder/index_36.gif)
![]()
![[Graphics:math/8_Autoencoder/index_38.gif]](math/8_Autoencoder/index_38.gif)
Image Inpainting
eCommerceGAN
Linear Generative Models: Earlier Days
Sparse Coding
Recognizing data (via discriminative models)
![]()
Creating data (via generative models)
![]()
![]()
![]()
![]()
Density Estimation
![]()
Prescribed models
![]()
![]()
Deep learning
![]()
![]()
Implicit models
![]()
Deep learning
![]()
![]()
![]()
Variational Autoencoders (VAE)
Autoendoer
![[Graphics:math/8_Autoencoder/index_53.gif]](math/8_Autoencoder/index_53.gif)
![]()
Limitation
![]()
Variational Autoencoder
![[Graphics:math/8_Autoencoder/index_56.gif]](math/8_Autoencoder/index_56.gif)
![]()
![]()
![]()
![]()
Training VAE with Reparameterizaion Trick
![[Graphics:math/8_Autoencoder/index_61.gif]](math/8_Autoencoder/index_61.gif)
Variational Autoencoder
![[Graphics:math/8_Autoencoder/index_62.gif]](math/8_Autoencoder/index_62.gif)
![]()
![]()
![]()
Probabilistic decoder (generator network)
![]()
![]()
Probabilistic encoder (inference network) for amortized variational inference
![]()
![]()
![]()
![]()
Training VAE
Variational lower-bound
![]()
![]()
![]()
![]()
![]()
Reconstruction cost
![]()
Penalty
![]()
Maximize the variational lower-bound on the average log-likelihood
![]()
Given
![]()
![]()
Goal
![]()
Model
![]()
![]()
Variational lower-boud
![]()
Two problems to be addressed
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Strochastic Gradient Variational Bayes
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Noisy Gradients
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Reparameterization Trick
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Score function gradients
![]()
![]()
Reparameterization gradients
![]()
![]()
VAE: Revisited
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Practice of VAEs
![]()
![]()

![]()
![]()
![]()
![]()
![]()
Shortcomings of VAEs
![]()
Over-regularization
![]()
![]()
Heuristics
![]()
Practical Implementation of VAEs:Summary
![]()
![]()
![]()
![]()
Noise Injection
![]()
Regularization
![]()
Regulaized Autoencoder (RAE)
Deterministic Reqularized Autoencoders
No noise injection
![]()
RAE
![]()
The loss for RAE is given by
![]()
![]()
![]()
![]()
![]() =
=![]() |z
|z![]()
![]()
Examples of ![]()
Tikhonov regularization
![]()
Gradient penalty
![]()
Spectal normalization
![]()
![]()
![]()
Ex-Post Density Estimation
No KL divergence term in RAE
![]()
![]()
![]()
![]()
Ex-post density estimation
![]()
![]()
![]()
![]()
![]()
ES-CVAE
Echo-State Conditional Variational Autoencoder
![]()
Echo State Networks
![]()
![]()
![]()
![]()
![]()
![]()
Our Model: ES-CVAE
![[Graphics:math/8_Autoencoder/index_191.gif]](math/8_Autoencoder/index_191.gif)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Variational Lower-Bound F on Log[p[![]() |
|![]() ]]
]]
![]()
![]()
![]()
![]()
![]()
Neural Statistician
![]()
Amortized inference
![]()
![]()
Variational inference = per-sample inference
Neural Statistician: A Bayesian Hierarchincal Model
![[Graphics:math/8_Autoencoder/index_210.gif]](math/8_Autoencoder/index_210.gif)
![]()
![]()
![]()
![]()
Neural Statistician = VAE for sets
![[Graphics:math/8_Autoencoder/index_215.gif]](math/8_Autoencoder/index_215.gif)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
5-way 1-shot
![]()
GAN (Generative Adversarial Network)
Adversarial training
![]()
![]()
![]()
![]()
Generative Adversarial Network
Generator, G[z;θ]:![]() →
→![]()
![]()
![]()
Discirminator, D[x;φ]:![]() →{0,1}
→{0,1}
![]()
![]()
![]()
![[Graphics:math/9_GAN/index_13.gif]](math/9_GAN/index_13.gif)
![]()
![]()
![]()
![]()
Training GAN
![]()
Training D
![]()
![]()
![]()
Training G
![]()
![]()
Two-player minimax game (for Nash equilibrium)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Unrolled GANs
![]()
![]()
![]()
Generating Images by GANs
DCGAN
![]()
![]()
![]()
Progressive Growing of GANS
![]()
Interesting Applications of GANs
GAN for single Image Super-Resolution
![]()
eCommerce GAN
Improved Techniques for Training GANs
Convergent Issue in GAN
Training GANs
![]()
![]()
![]()
![]()
![]()
![]()
Problems in GAN Training
Non-Convergence
![]()
Mode collapsing
![]()
Diminished gradient
![]()
Feature Matching to Train G
![]()
![]()
![]()
![]()
![]()
Denoising Auto-Encoder
![[Graphics:math/9_GAN/index_57.gif]](math/9_GAN/index_57.gif)
![]()
GAN Trained with Denoising Feature Matching
Training G
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
An Information-Theoretic Extension of GAN
![]()
Disentangled Representation
![]()
![]()
![]()
Disentangled = Interpretable and Factorized
Information Maximization
InfoGAN
![]()
![]()
![]()
![]()
InfoGAN
![]()
![]()
![]()
![]()
Training InfoGAN
Train the discriminator D[x]
![]()
Train the generator G[z,c]
![]()
![]()
Variational Infomax
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Conditional GAN
![]()
![]()
Generator
![]()
Discriminator
![]()
Optimization
![]()
Image-to-image translation
Map Edges to Photo via cGAN
Unpaired Image to Image Translation
![]()
Cycle-Consistency
![]()
![]()
![]()
![]()
![[Graphics:math/9_GAN/index_100.gif]](math/9_GAN/index_100.gif)
![[Graphics:math/9_GAN/index_101.gif]](math/9_GAN/index_101.gif)
Adversarial Loss + Cycle Consistency Loss
Adversarial loss for G:X→Y and F:Y→X
![]()
![]()
Cycle consistency loss
![]()
Summary
| AE | VAE | GAN |
| □ | likelihood-based | likelihood-free |
| Deterministic Encoder & Decoder | Probabilistic Encoder & Decoder | Deterministic Decoder |
| □ | □ | GAN+Encoder=ALI (Adevarsarially learned inference)Bi-GAN |
| □ | Probabilistic Decoder | Generator network |
| □ | Blurry images | Sharp-looking image |
| □ | x | Mode-collapsing problem |
GANs with Encoder Networks
Adversarially Learned Inference
![[Graphics:math/9_GAN/index_105.gif]](math/9_GAN/index_105.gif)
Encoder joint distribution
![]()
Decoder joint distribution
![]()
Match these two joint distributions
The miniax game
![]()
Semi-Supervised Learning with GANs
Small amount of labeled data
![]()
![]()
![]()
Semi-Supervised Learning with GAN
Classifier for K classes
![]()
GAN
![]()
Loss
![]()
![]()
![]()
![]()
![]()
Hyperparameter Optimization
Bayesian optimization
Optimization of Black-Box Functions
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Regret
Instantaneous regret
![]()
Cumulative regret (in the bandit setting)
![]()
Simple regret: (in the optimization setting)
![]()
No regret algorithms in the bandit setting: ![]()
![]() =0
=0
![]()
Hyperparameter Optimization
Hyperparameters ![]()
![]()
![]()
![]()
![]()
![]()
![]()
SigOput
![]()
Objective
![]()
Search space
![]()
Observations
![]()
Automated machine learning
Objective
![]()
Search space
![]()
![]()
![]()
Observations
![]()
Clinical drug trials in healthcare
Objective
![]()
Search space
![]()
![]()
Observations
![]()
Active user modeling
Objective
![]()
Search space (x)
![]()
Observations (f[x])
![]()
Hyperparameters
Model parameters
![]()
![]()
Hyperparameters
![]()
![]()
Auto ML ⊃ Hyperparameter Optimization ⊃ Neural Architecture Search
Search over Configuration Space
![]()
Grid serach
Random serach
Any more efficient method in terms of the number of eveluations?
![]()
AutoML
![]()
Feature processing
Model/algorithm selection
Hyperparameter tuning
Many companies are using AutoML
![]()
![]()
Microsoft
![]()
Amazon
![]()
AutoGluon: Introduced by Amazon in January, 2020
![]()
Democratizes the task of ML
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Bayesian Optimization
Surrogate function
![]()
![]()
Auquisition function
![]()
![]()
Surrogate model
![[Graphics:math/10_HyperparameterOptimization/index_62.gif]](math/10_HyperparameterOptimization/index_62.gif)
![]()
GP regression
Regression
![]()
![]()
Random function = Gaussian Process
![]()
![]()
![]()
![]()
![]()
![]()
Choice of Kernels
Squared exponential kernel (Gaussian kernel)
![]()
![]()
![]()
![]()
Matern Kernel
![]()
![]()
Few Things about GP
Pros
![]()
![]()
Cons
![]()
![]()
Besides GP regression, as surrogate models, you can also use
Random forests
![]()
![]()
Neural networks
![]()
![]()
![]()
Alternative Surrogate Model: Random Forests
![]()
![]()
![]()
![]()
More alternative surrogate models include
Mondrian forest regression
![]()
Neural processes
![]()
Algorithm Outline: Bayesian Optimization
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Handling Categorical or Integer-Valued Variables
Spearmint
Integer-valued variables
![]()
Categorical variables
![]()
A naive approach
![]()
![]()
BayesOpt
![]()
![]()
A navie approach
![]()
![]()
Acquisition Functions
![]()
![]()
![]()
![]()
Utility Function
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Utility and Acquisition Functions
Probability of Improvement (PI)
![]()
Expected Improvement (EI)
![]()
GP Upper Confidence Bound (GP-UCB)
![]()
Expected Improvement
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Exploration-Exploitation Trade-Off in EI
![]()
![]()
GP-UCB
![]()
![]()
![]()
![]()
![]()
Compressed Sensing
NAS in practice
![]()
Application to Soft-Voting in Ensemble
![]()
![]()
Neural Process
Generative query network (GQN)
Generalizations of GQN framework
![]()
![]()
![]()
![]()
Wanted
![]()
Gaussian Processes
![]()
![]()
![]()
(non-Bayesian) deep neural networks (DNNs)
![]()
![]()
![]()
Neural processes
![]()
Generative Query Network
![]()
Conditional Neural Processes
Motivation
CNPs combine benefits of NNs and GPs
![]()
![]()
Supervised Learning: Data Description
Observed data
![]()
Target inputs
![]()
Underlying ground truth function
![]()
Task
![]()
Supervised Learning
![]()
![]()
CNP
Embedding
![]()
Aggregation
![]()
Parameterized approximating function (e.g., neural networks)
![]()
GP vs CNP
Gaussian processes
![]()
![]()
![]()
![]()
Conditional neural processes
![]()
![]()
CNP: Model
![]()
![]()
![]()
![]()
![]()
CNP: Architecture
Architecture
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The mean aggregation is used
![]()
Neural Processes
Motivation
![]()
| NN | GP | CNP | NP | |
| Can fit more than one function at test time(distribution over functions) | x | O | O | O |
| Computationally cheap at test time | O | x | O | O |
| Can sample entire coherent functions | x | O | x | O |
Neural Networks vs Gaussian Processes
NNs
![]()
GPs
![]()
Architecture
Encoder
![]()
Aggregator
![]()
Conditional decoder
![]()
Training
![]()
![]()
3 Dimension Space
3 D Equation
Point
![]()
![]()
Line Equation
![]()
Plane(Normal Vector)
![]()
Line Equation
![]()
Plane Equation
![]()
![]()
![]()
![]()
![]()
![]()
![]()
3 Point → Plane (Normal Vector)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![N == Det[({{e_1, e_2, e_3, e_4}, {x_0, y_0, z_0, 1}, {x_1, y_1, z_1, 1}, {x_2, y_2, z_2, 1}})]](math/20_3D_Space/index_27.gif)
![]()
![]()
![]()
![]()
3 Plane (Normal Vector) → Point
![]()
![]()
![]()
![]()
![]()
![P == Det[({{e_1, e_2, e_3, e_4}, {a_0, b_0, c_0, d_0}, {a_1, b_1, c_1, d_1}, {a_2, b_2, c_2, d_2}})]](math/20_3D_Space/index_37.gif)
![]()
![]()
![]()
![]()
![]()
2 Plane (Normal Vector) → Line
![]()
![]()
![]()
![== Det[({{e_1, e_2, e_3}, {a_0, b_0, c_0}, {a_1, b_1, c_1}})]](math/20_3D_Space/index_46.gif)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
2 Line→ Plane (Normal Vector)
![]()
![]()
![]()
![]()
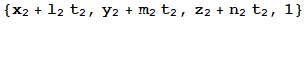
![]()
![]()
![]()
2 Line Angle
![]()
Equation Solution
![]()
![]()
![{a_3, b_3, c_3, d_3} == Det[({{e_1, e_2, e_3, e_4}, {a_0, b_0, c_0, d_0}, {a_1, b_1, c_1, d_1}, {a_2, b_2, c_2, d_2}})]](math/20_3D_Space/index_66.gif)
![]()
Homogeneous Coordinates Matrix
Reduction, Extension, Movement
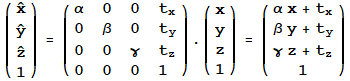
Rotation
z Axis Rotation - ![]() [θ]
[θ]
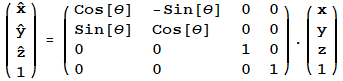
y Axis Rotation - ![]() [θ]
[θ]
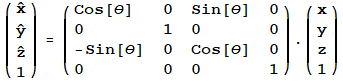
x Axis Rotation - ![]() [θ]
[θ]
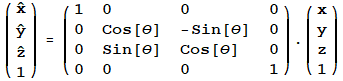
Transport [ESC]tr[ESC]
Matrix Property
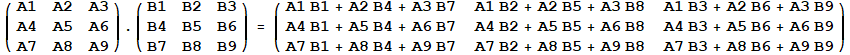
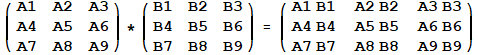
Form
![]()
![]()
![]()
![]()
![]()
![]()
Determinant (행렬식)
![]()
![| {{a_11, a_12, a_13}, {a_21, a_22, a_23}, {a_31, a_32, a_33}} | = Det[({{a_11, a_12, a_13}, {a_21, a_22, a_23}, {a_31, a_32, a_33}})]](math/20_3D_Space/index_85.gif)
![]()
![]()
Vector
![]()
![]()
![]()
![]()
![]()
Vector Angle
![]()
Vector <U,V> ([ESC]*[ESC])
![]()
Vector Inner Product (Dot[{![]() ,
,![]() ,
,![]() },{
},{![]() ,
,![]() ,
,![]() }], |U||V|Cos[θ] )
}], |U||V|Cos[θ] )
![]()
Vector External Product (Cross[{![]() ,
,![]() ,
,![]() },{
},{![]() ,
,![]() ,
,![]() }], [ESC]cross[ESC])
}], [ESC]cross[ESC])
![]()
![= | {{e_1, e_2, e_3}, {u_1, u_2, u_3}, {v_1, v_2, v_3}} | = Det[({{e_1, e_2, e_3}, {u_1, u_2, u_3}, {v_1, v_2, v_3}})]](math/20_3D_Space/index_109.gif)
![]()
![]()
Vector Property
![]()
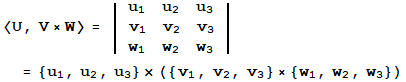
![]()
Area
![Area = 1/2Det[({{x_1, y_1, 1}, {x_2, y_2, 1}, {x_3, y_3, 1}})] = (x_3 (y_1 - y_2) + x_1 (y_2 - y_3) + x_2 (-y_1 + y_3))/2](math/20_3D_Space/index_115.gif)
Line & Point (Up|Down)
![Det[({{x_1, y_1, 1}, {x_2, y_2, 1}, {x_3, y_3, 1}})] = x_3 (y_1 - y_2) + x_1 (y_2 - y_3) + x_2 (-y_1 + y_3)](math/20_3D_Space/index_116.gif)
![Det[({{x_1, y_1, 1}, {x_2, y_2, 1}, {x_3, y_3, 1}})] <0 : Right Turn](math/20_3D_Space/index_117.gif)
![Det[({{x_1, y_1, 1}, {x_2, y_2, 1}, {x_3, y_3, 1}})] >0 : Left Turn](math/20_3D_Space/index_118.gif)
Determinant (Det)
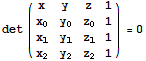
Cofactor expansion along the first row
![]()
![]()
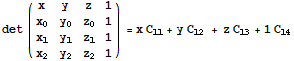
Equation of a Plane
a x + b y + c z + d = 0
![]()
![]()
![]()
![]()
3x3 Determinant (Sarrus' Rule)
![]()
Connection between Cross Product/Scalar Triple Product and Determinant
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
In the beginning God created the heaven and the earth.
| 이름 | 유경환 (Yoo Kyunghwan) |  |
 |
| 전공 | 수학, 컴퓨터, 로봇 | ||
| 전자메일 | yookyunghwan@gmail.com |
| 연도 | 학교 | 학력 | 전공 |
| 2013.03 ~ Present | Dankook University | in Doctor Student of Engineering | Computer Science and Engineering |
| 2003.08 ~ 2006.05 | University of Southern California | Master of Science | Computer Science (Intelligent Robotics) |
| 1999.03 ~ 2003.02 | Korea University | Bachelor of Science | Mathematics & Computer Science |
Copyright © 2020 RMATH. All Right Reserved.